Does anyone remember word clouds? Word clouds—also known as tag clouds—were popular from mid-2000s to around the early 2010s. (At least, I remember them being heavily featured in a “History and New Media” class I took in college.) They are visual representations of textual data, wherein the size and sometimes color of each word or tag represents the frequency of that word within a specific text.
For a while now, I’ve been interested in how I might be able to visualize data from my family tree in the form of a word cloud. In particular, as someone with a lifelong fascination with given names, I was curious what a name-based word cloud using data from my family tree would look like. What were the most common given names in my tree?
To answer this, I used a couple of different tools. I started with my RootsMagic software program, generating a custom report that had only two columns: Surname and Given Name. I opened this report as a basic text file and then transferred that data to an Excel spreadsheet. From there, I deleted the Surname column, as I was purely interested in given names. From there, all I had to do was find a free word cloud program to upload my data to. In retrospect, I could have generated a list of just given names from the start and saved myself one step, and may have even been able to feed the basic text file into a word cloud generator.
I tried two different platforms, both of which were freely available online. The first was the aptly-named FreeWordCloudGenerator. I imported my data as a .csv file and asked it to visualize the top 95 words (in this case, names). This program also let me pick a color palette and font, which was fun but not entirely necessary for this exercise.
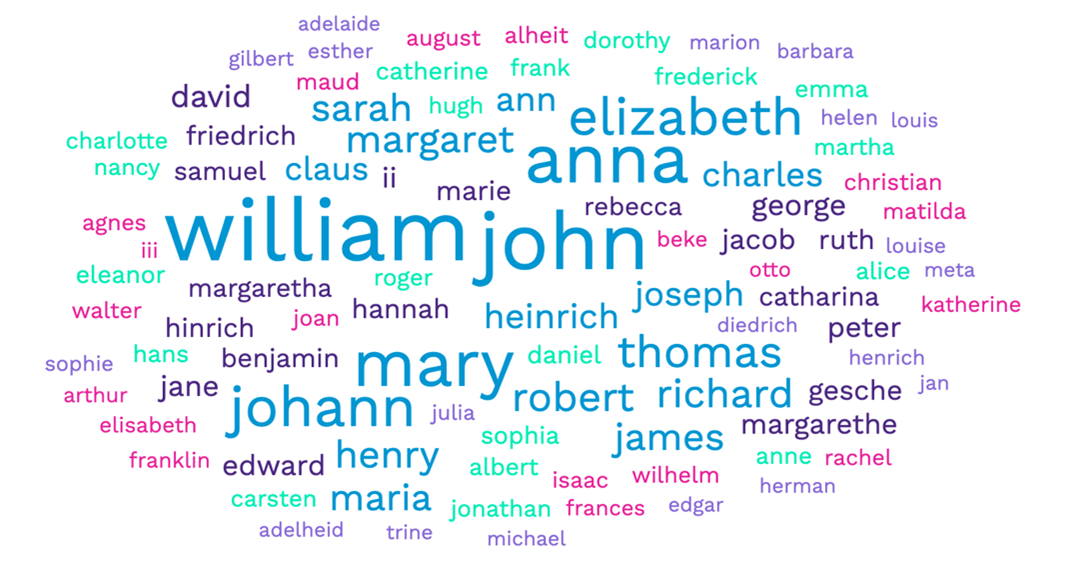
For my second program, I chose Voyant, which was one of the tools discussed in my college course. Voyant does more than just word clouds, but for this exercise I largely ignored the other tools. I uploaded my Excel file to Voyant and once again asked it to show me the top 95 terms.

Voyant spit out a couple of data points for me—I could easily see that William, Mary, John, and Anna used the largest font size from both programs, but Voyant confirmed that these were in fact the most frequent terms. William appeared 161 times, John 144, Anna 119, Mary 112, and Johann 90. Voyant’s “Reader” view also allowed me to hover over any term in my uploaded text and see how frequently that term appeared—though I’m not surprised, I found that my own name was totally unique in my tree.
This quick-and-dirty method could probably be refined—for example, my list included names with numerals like “I,” “II,” and “III,” which you might not want in the long run. The Voyant cloud also shows a couple of stray letters, like “H,” “J,” and “L,” which probably represent middle initials for ancestors with unknown middle names.
For a final test, I created a new report in RootsMagic, this time using the “mark group” feature to select only my direct ancestors from the past 12 generations. This eliminated collateral lines I had researched as well as the few medieval lineages in my tree. I uploaded my data to the Free Word Cloud Generator again and, because I was working with a smaller dataset, I set my maximum number of terms to 30 this time. The same names appear at the top but, with only my direct ancestors included, my father’s German heritage and their penchant for using the names “Johann” and “Anna” as first given names is apparent. Johann is clearly #1, followed by Anna, William, John, Mary, and Claus.

As a data visualization exercise, this was a fun, quick, and easy new way to think about my family! What does your family’s name cloud look like?
